Ustawianie zmienych środowiskowych procesu
W poprzednim poście opisałem gdzie w pamięci procesu znajdują się zmienne środowiskowe. Niestety bezpośrednie ich modyfikowanie nie przyniosło oczekiwanego efektu ze względu cache wprowadzony w podstawowych bibliotekach systemowych. Na szczęście nie oznacza to końca projektu a dopiero początek wspaniałej przygody ;).
Jedynym pewnym sposobem korzystania ze zmiennych środwiskowych jest korzystanie z dostarczonych funkcji, które operują na własnej przestrzeni adresowej. Można je jednak połączyć z mechanizmami systemowi pozwalającymi na wykonanie kodu w kontekście innego procesu poprzez stworzenie w nim nowego wątku (technika ta powinna być znana tym, którzy tworzyli hooki funkcji systemowych). Dzięki temu możliwe będzie wykonanie dowolnego kodu, w tym zmiana zmiennych środowiskowych. Oczywiście rozwiązanie problemu wymaga pokanania kilku przeszkód natury technicznej.
Pierwszym z nich jest konieczność podania adresu entrypointa wątku, która musi się znajdować już w przestrzeni adresowej docelowego procesu. Niesety, większość programistów nie będzie na tyle wspmaniałomyślna, żeby uwzględnić w swoim kodzie funkcję przewidzanią do współpracy z Patherem. Problem można rozwiązać na dwa sposoby: dynamiczne wygenerowanie funkcji oraz załadowanie DLL-ki wskazując funkcję LoadLibrary z kernel32.dll jako entrypoint wątku, która po wczytniu zacznie wykonywać swoją funkcję DllMain, czyli nasz kod. Dynamiczne wygenerowanie funkcji jest interesującym zagadnieniem jednak wiąże się z kolejnymi kłopotami: poprawność kodu maszynowego, ochrona pamięci, itp. Na potrzeby tego projektu wykorzystanie DLL-ki powinno okazać się wystarczające.
Po załadowaniu DLL-ki możemy zrobić co tylko nam się podoba ze stanem docelowego procesu. Powstaje jednak pytanie skąd wziąć nową wartość zmiennej PATH lub jak przesłać jej aktualną wartość do Pathera? Z pomocą przychodzą nazwane potoki (named pipes) pozwalające na dwukierunkową komunikację między procesami poprzez plikopodoby interfejs. Dzięki temu możliwa będzie wymiana dowolnych danych między Patherem a procesem docelowym.
Cały pomysł najlepiej przedstawi schemat:
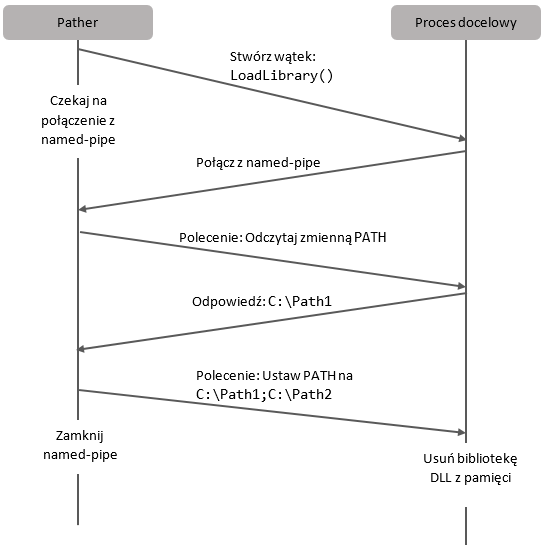
W następnym poście pojawi się (nareszcie!) trochę kodu i implementacja opisanego podejścia.